
DeepMind and several research partners have released a database containing the 3D structures of nearly every protein in the human body, as computationally determined by the breakthrough protein folding system demonstrated last year, AlphaFold. The freely available database represents an enormous advance and convenience for scientists across hundreds of disciplines and domains, and may very well form the foundation of a new phase in biology and medicine.
The AlphaFold Protein Structure Database is a collaboration between DeepMind, the European Bioinformatics Institute, and others, and consists of hundreds of thousands of protein sequences with their structures predicted by AlphaFold — and the plan is to add millions more to create a “protein almanac of the world.”
“We believe that this work represents the most significant contribution AI has made to advancing the state of scientific knowledge to date, and is a great example of the kind of benefits AI can bring to society,” said DeepMind founder and CEO Demis Hassabis.
From genome to proteomeIf you’re not familiar with proteomics in general — and it’s quite natural if that’s the case — the best way to think about this is perhaps in terms of another major effort: that of sequencing the human genome. As you may recall from the late ’90s and early ’00s, this was a huge endeavor undertaken by a large group of scientists and organizations across the globe and over many years. The genome, finished at last, has been instrumental to the diagnosis and understanding of countless conditions, and in the development of drugs and treatments for them.
It was, however, just the beginning of the work in that field — like finishing all the edge pieces of a giant puzzle. And one of the next big projects everyone turned their eyes toward in those years was understanding the human proteome — which is to say all the proteins used by the human body and encoded into the genome.
The problem with the proteome is that it’s much, much more complex. Proteins, like DNA, are sequences of known molecules; in DNA these are the handful of familiar bases (adenine, guanine, etc), but in proteins they are the 20 amino acids (each of which is coded by multiple bases in genes). This in itself creates a great deal more complexity, but it’s only the start. The sequences aren’t simply “code” but actually twist and fold into tiny molecular origami machines that accomplish all kinds of tasks within our body. It’s like going from binary code to a complex language that manifests objects in the real world.
Practically speaking this means that the proteome is made up of not just 20,000 sequences of hundreds of acids each, but that each one of those sequences has a physical structure and function. And one of the hardest parts of understanding them is figuring out what shape is made from a given sequence. This is generally done experimentally using something like x-ray crystallography, a long, complex process that may take months or longer to figure out a single protein — if you happen to have the best labs and techniques at your disposal. The structure can also be predicted computationally, though the process has never been good enough to actually rely on — until AlphaFold came along.
Alphabet’s DeepMind achieves historic new milestone in AI-based protein structure prediction
Taking a discipline by surprise
Without going into the whole history of computational proteomics (as much as I’d like to), we essentially went from distributed brute-force tactics 15 years ago — remember Folding@home? — to more honed processes in the last decade. Then AI-based approaches came on the scene, making a splash in 2019 when DeepMind’s AlphaFold leapfrogged every other system in the world — then made another jump in 2020, achieving accuracy levels high enough and reliable enough that it prompted some experts to declare the problem of turning an arbitrary sequence into a 3D structure solved.
I’m only compressing this long history into one paragraph because it was extensively covered at the time, but it’s hard to overstate how sudden and complete this advance was. This was a problem that stumped the best minds in the world for decades, and it went from “we maybe have an approach that kind of works, but extremely slowly and at great cost” to “accurate, reliable, and can be done with off the shelf computers” in the space of a year.
Image Credits: DeepMind
The specifics of DeepMind’s advances and how it achieved them I will leave to specialists in the fields of computational biology and proteomics, who will no doubt be picking apart and iterating on this work over the coming months and years. It’s the practical results that concern us today, as the company employed its time since the publication of AlphaFold 2 (the version shown in 2020) not just tweaking the model, but running it… on every single protein sequence they could get their hands on.
The result is that 98.5 percent of the human proteome is now “folded,” as they say, meaning there is a predicted structure that the AI model is confident enough (and importantly, we are confident enough in its confidence) represents the real thing. Oh, and they also folded the proteome for 20 other organisms, like yeast and E. coli, amounting to about 350,000 protein structures total. It’s by far — by orders of magnitude — the largest and best collection of this absolutely crucial information.
All that will be made available as a freely browsable database that any researcher can simply plug a sequence or protein name into and immediately be provided the 3D structure. The details of the process and database can be found in a paper published today in the journal Nature.
“The database as you’ll see it tomorrow, it’s a search bar, it’s almost like Google search for protein structures,” said Hassabis in an interview with TechCrunch.”You can view it in the 3D visualizer, zoom around it, interrogate the genetic sequence… and the nice thing about doing it with EMBL-EBI is it’s linked to all their other databases. So you can immediately go and see related genes, And it’s linked to all these other databases, you can see related genes, related in other organisms, other proteins that have related functions, and so on.”
Image Credits: DeepMind
“As a scientist myself, who works on an almost unfathomable protein,” said EMBL-EBI’s Edith Heard (she didn’t specify what protein), “it’s really exciting to know that you can find out what the business end of a protein is now, in such a short time — it would have taken years. So being able to access the structure and say ‘aha, this is the business end,’ you can then focus on trying to work out what that business end does. And I think this is accelerating science by steps of years, a bit like being able to sequence genomes did decades ago.”
So new is the very idea of being able to do this that Hassabis said he fully expects the entire field to change — and change the database along with it.
“Structural biologists are not yet used to the idea that they can just look up anything in a matter of seconds, rather than take years to experimentally determine these things,” he said. “And I think that should lead to whole new types of approaches to questions that can be asked and experiments that can be done. Once we start getting wind of that, we may start building other tools that cater to this sort of serendipity: What if I want to look at 10,000 proteins related in a particular way? There isn’t really a normal way of doing that, because that isn’t really a normal question anyone would ask currently. So I imagine we’ll have to start producing new tools, and there’ll be demand for that once we start seeing how people interact with this.”
That includes derivative and incrementally improved versions of the software itself, which has been released in open source along with a great deal of development history. Already we have seen an independently developed system, RoseTTAFold, from researchers at the University of Washington’s Baker Lab, which extrapolated from AlphaFold’s performance last year to create something similar yet more efficient — though DeepMind seems to have taken the lead again with its latest version. But the point was made that the secret sauce is out there for all to use.
Researchers match DeepMind’s AlphaFold2 protein folding power with faster, freely available model
Practical magic
Although the prospect of structural bioinformaticians attaining their fondest dreams is heartwarming, it is important to note that there are in fact immediate and real benefits to the work DeepMind and EMBL-EBI have done. It is perhaps easiest to see in their partnership with the Drugs for Neglected Diseases Institute.
The DNDI focuses, as you might guess, on diseases that are rare enough that they don’t warrant the kind of attention and investment from major pharmaceutical companies and medical research outfits that would potentially result in discovering a treatment.
“This is a very practical problem in clinical genetics, where you have a suspected series of mutations, of changes in an affected child, and you want to try and work out which one is likely to be the reason why our child has got a particular genetic disease. And having widespread structural information, I am almost certain will improve the way we can do that,” said DNDI’s Ewan Birney in a press call ahead of the release.
Ordinarily examining the proteins suspected of being at the root of a given problem would be expensive and time-consuming, and for diseases that affect relatively few people, money and time are in short supply when they can be applied to more common problems like cancers or dementia-related diseases. But being able to simply call up the structures of ten healthy proteins and ten mutated versions of the same, insights may appear in seconds that might otherwise have taken years of painstaking experimental work. (The drug discovery and testing process still takes years, but maybe now it can start tomorrow for Chagas disease instead of in 2025.)
Illustration of RNA polymerase II ( a protein) in action in yeast.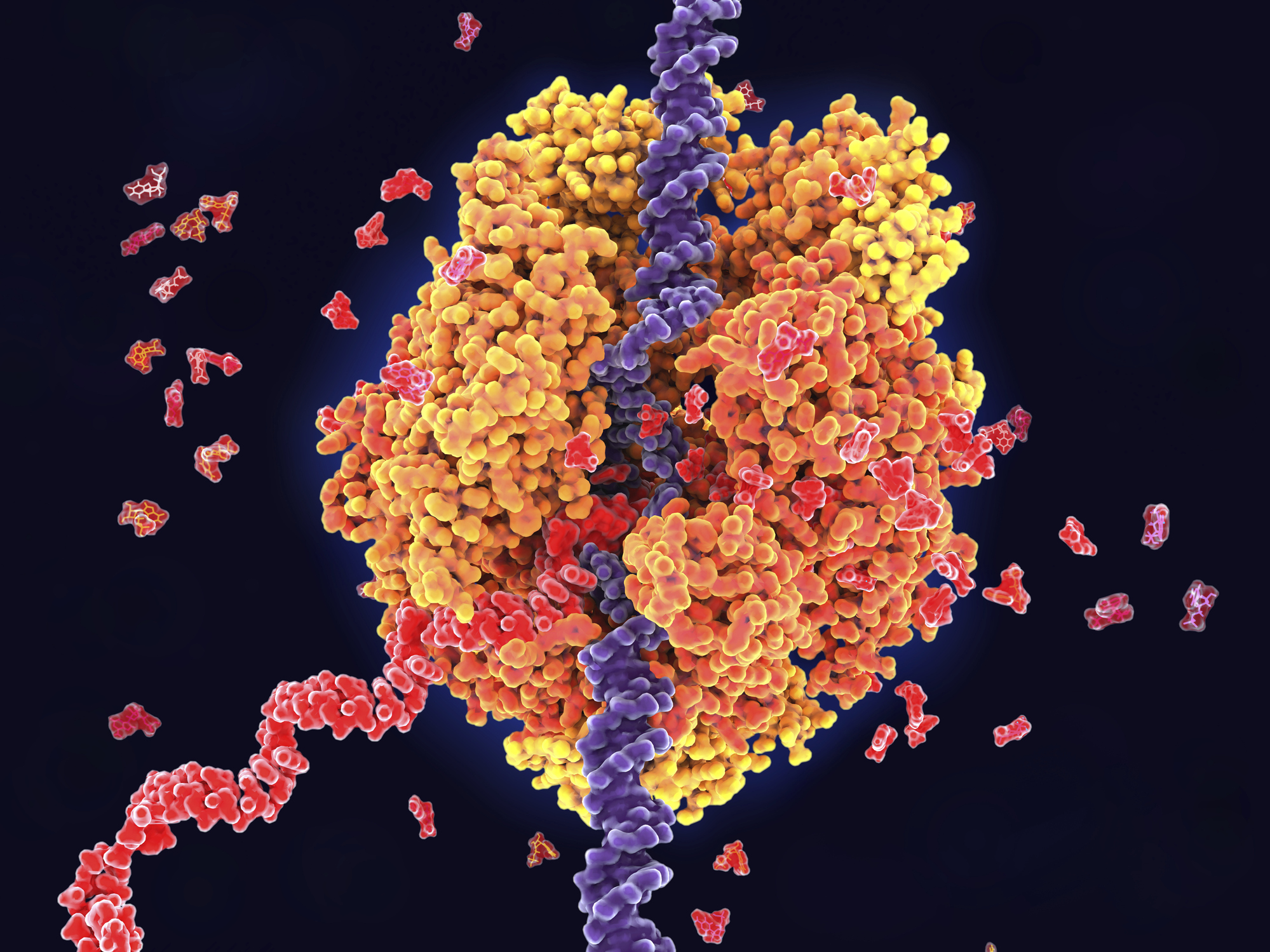
Lest you think too much is resting on a computer’s prediction of experimentally unverified results, in another, totally different case, some of the painstaking work had already been done. John McGeehan of the University of Portsmouth, with whom DeepMind partnered for another potential use case, explained how this affected his team’s work on plastic decomposition.
“When we first sent our seven sequences to the DeepMind team, for two of those we already had experimental structures. So we were able to test those when they came back, and it was one of those moments, to be honest, when the hairs stood up on the back of my neck,” said McGeehan. “Because the structures that they produced were identical to our crystal structures. In fact, they contained even more information than the crystal structures were able to provide in certain cases. We were able to use that information directly to develop faster enzymes for breaking down plastics. And those experiments are already underway, immediately. So the acceleration to our project here is, I would say, multiple years.”
The plan is to, over the next year or two, make predictions for every single known and sequenced protein — somewhere in the neighborhood of a hundred million. And for the most part (the few structures not susceptible to this approach seem to make themselves known quickly) biologists should be able to have great confidence in the results.
Inspecting molecular structure in 3D has been possible for decades, but finding that structure in the first place is difficult.
The process AlphaFold uses to predict structures is, in some cases, better than experimental options. And although there is an amount of uncertainty in how any AI model achieves its results, Hassabis was clear that this is not just a black box.
“For this particular case, I think explainability was not just a nice-to-have, which often is the case in machine learning, but it was a must-have, given the seriousness of what we wanted it to be used for,” he said. “So I think we’ve done the most we’ve ever done on a particular system to make the case with explainability. So there’s both explainability on a granular level on the algorithm, and then explainability in terms of the outputs, as well the predictions and the structures, and how much you should or shouldn’t trust them, and which of the regions are the reliable areas of prediction.”
Nevertheless his description of the system as “miraculous” attracted my special sense for potential headline words. Hassabis said that there’s nothing miraculous about the process itself, but rather that he’s a bit amazed that all their work has produced something so powerful.
“This was by far the hardest project we’ve ever done,” he said. “And, you know, even when we know every detail of how the code works, and the system works, and we can see all the outputs, it’s still just still a bit miraculous when you see what it’s doing… that it’s taking this, this 1D amino acid chain and creating these beautiful 3D structures, a lot of them aesthetically incredibly beautiful, as well as scientifically and functionally valuable. So it was more a statement of a sort of wonder.”
Fold after foldThe impact of AlphaFold and the proteome database won’t be felt for some time at large, but it will almost certainly — as early partners have testified — lead to some serious short-term and long-term breakthroughs. But that doesn’t mean that the mystery of the proteome is solved completely. Not by a long shot.
As noted above, the complexity of the genome is nothing compared to that of the proteome at a fundamental level, but even with this major advance we have only scratched the surface of the latter. AlphaFold solves a very specific, though very important problem: given a sequence of amino acids, predict the 3D shape that sequence takes in reality. But proteins don’t exist in a vacuum; they’re part of a complex, dynamic system in which they are changing their conformation, being broken up and reformed, responding to conditions, the presence of elements or other proteins, and indeed then reshaping themselves around those.
In fact a great deal of the human proteins AlphaFold gave only a middling level of confidence to its predictions for may be fundamentally “disordered” proteins that are too variable to pin down the way a more static one can be (in which case the prediction would be validated as a highly accurate predictor for that type of protein). So the team has its work cut out for it.
“It’s time to start looking at new problems,” said Hassabis. “Of course, there are many, many new challenges. But the ones you mentioned, protein interaction, protein complexes, ligand binding, we’re working actually on all these things, and we have early, early stage projects on all those topics. But I do think it’s worth taking, you know, a moment to just talk about delivering this big step… it’s something that the computational biology community’s been working on for 20, 30 years, and I do think we have now broken the back of that problem.”
